
Physical AI 101: A Beginner’s Field Guide to World Model
A beginner-friendly field guide to AI world models: what they are, how they evolved, who is building them, where funding is going, and why they matter for robotics, autonomous vehicles, gaming, 3D worlds, and physical AI.

World models sound like sci-fi nonsense, but the idea is simple.
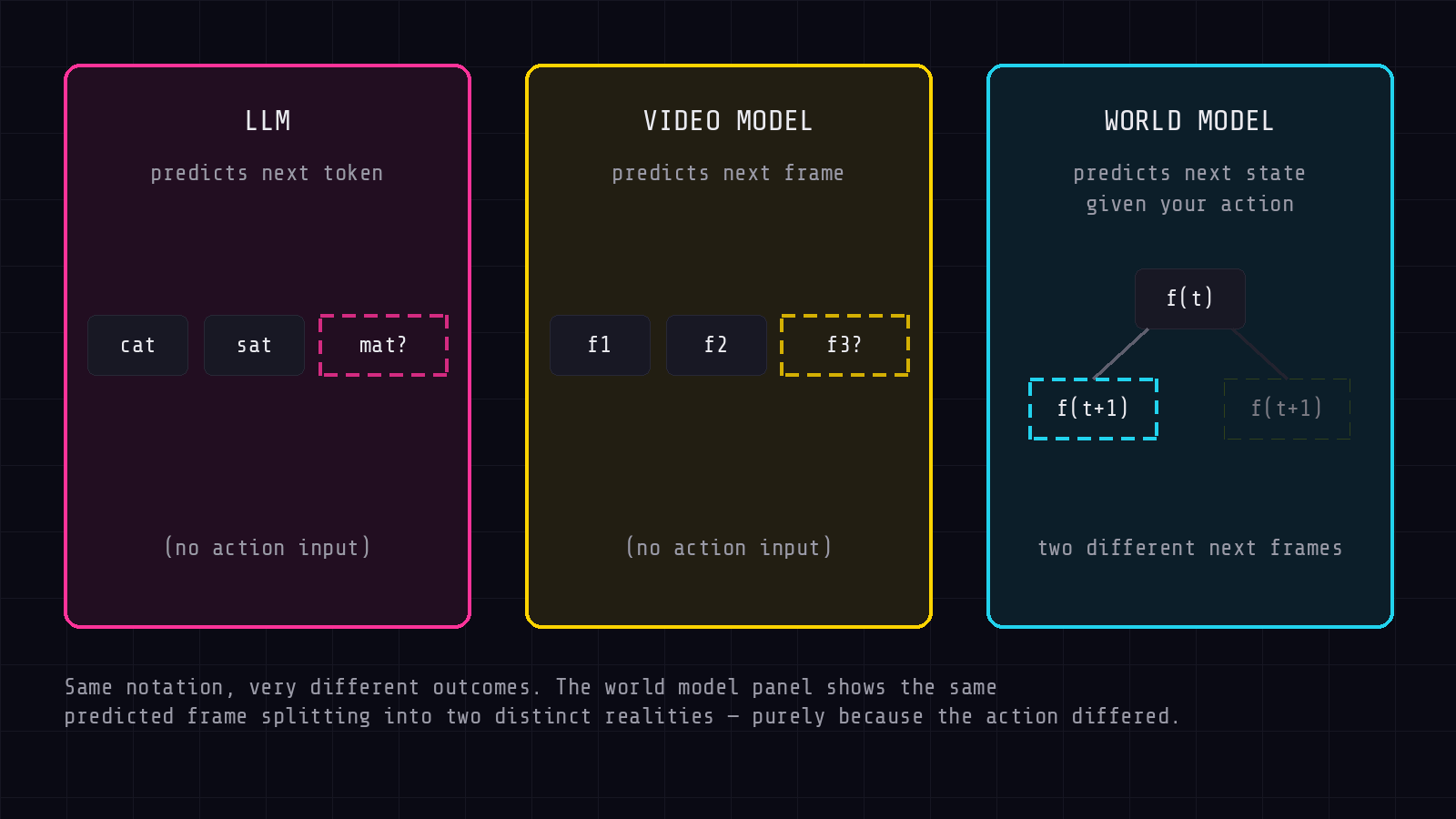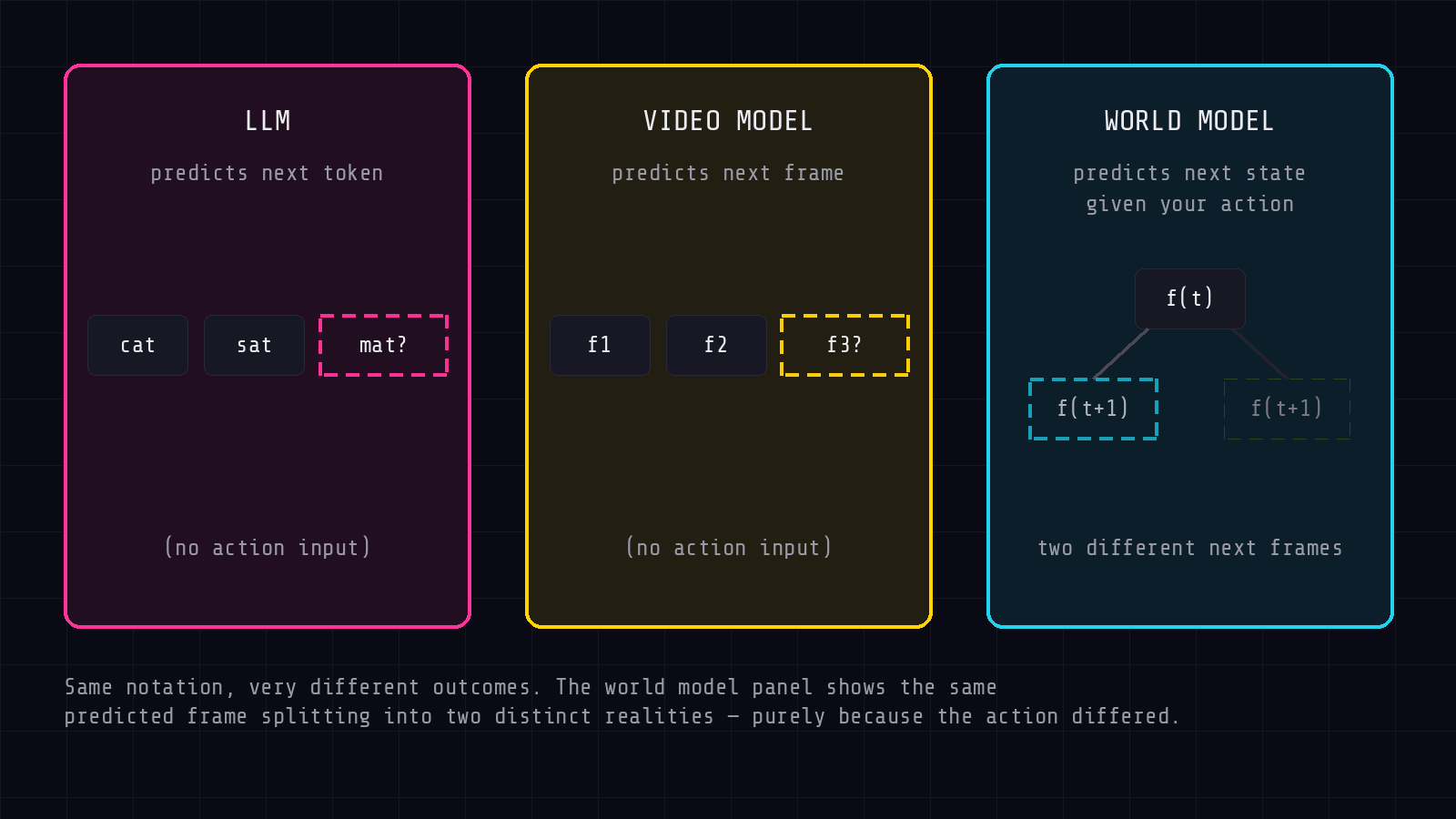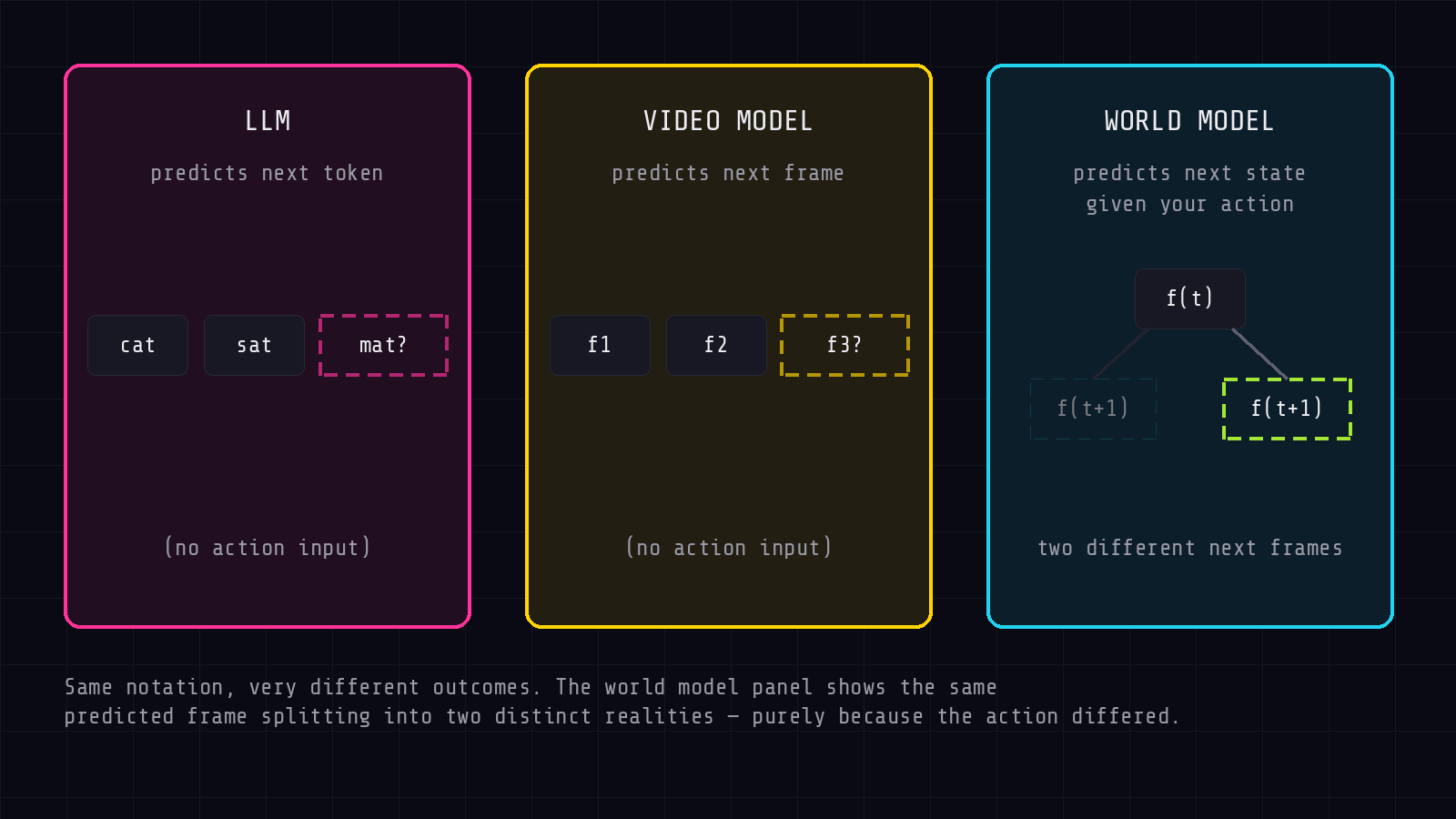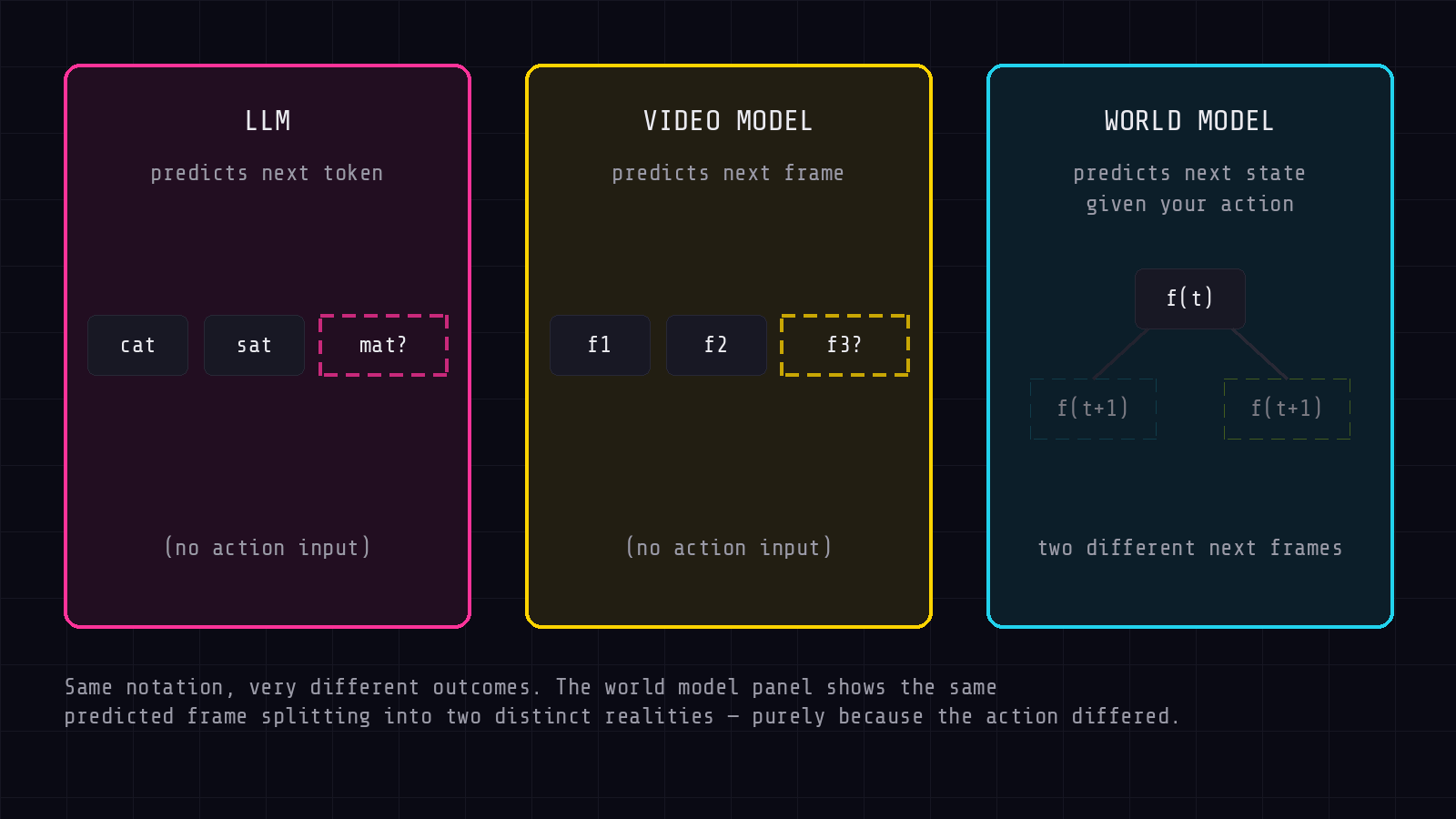
A chatbot predicts the next word. A video model predicts the next frame. A world model tries to predict what happens next after something acts.
That is why people care. If AI is going to control robots, cars, games, factories, or virtual worlds, it needs more than language. It needs a rough sense of reality.
Or at least, that is the dream. Reality, as usual, is being dramatic.
Part 1: What Is a World Model? From First Principles
The core idea: an internal simulator of reality
Imagine knocking a glass of water off a table. Before it happens, you can already picture the glass tipping, falling, breaking, and spilling water. You are not physically running a full physics engine in your brain, but you have a compressed internal model of how the world works.
A world model is the machine version of that idea. It builds an internal representation of an environment and uses it to predict how that environment will change, especially in response to actions.
The important phrase is action-conditioned simulation. The model does not only predict what comes next. It predicts what comes next if an action is taken.
What makes it different from an LLM
A large language model predicts the next token. That makes it extremely good at text, summarising, writing, explaining, and following instructions. But language is a compressed representation of reality. The physical world is continuous, noisy, spatial, and full of consequences.
An LLM can explain what may happen if a glass falls. But it does not naturally simulate the trajectory, collision, spill pattern, or where the pieces land. It can reason about physics linguistically, but it is not built as a physical simulator.
This is why world models matter for robotics and autonomous vehicles. A robot does not only need to understand the sentence “pick up the mug.” It needs to know how the mug sits in space, what happens if it grips too loosely, and which movement is safest.
What makes it different from a video generator
This is the more subtle distinction. A video model predicts frames. It can generate realistic-looking motion, lighting, and objects. But if the user cannot act inside the scene, the model is still closer to video than a world.
A world model must respond to actions. If you turn left, the world should reveal what is on the left. If a car brakes, the simulated scene should change accordingly. If a robot pushes an object, the model should predict the object’s response.
| Model type | What it predicts | Example |
|---|---|---|
| Language model | Next token | “The car turned...” |
| Video model | Next frame | A generated clip continues |
| World model | Next state after an action | A robot pushes a box and predicts where it moves |
A video model gives you something to watch. A world model gives you something to act inside.
The two philosophies: understanding vs. prediction
A useful fault line runs through the field.
Prediction models try to draw what comes next. Systems like Sora, Genie, Oasis, and other generative video/world systems are visually impressive because they generate future frames or scenes. This makes them easier to productise in creative tools, gaming, and interactive media.
Understanding models try to learn the underlying structure of the world. JEPA-style models and Dreamer-style systems predict in latent space rather than reconstructing pixels. The argument is that raw pixels include too much detail that is irrelevant or unpredictable.
My practical read: prediction wins attention first, but understanding is what makes the category valuable for robotics and planning.
The World Labs taxonomy: renderers, simulators, planners
“World model” is becoming an overloaded term. A useful way to separate the field is by asking what layer the model serves.
| Layer | Output | Main question | Example direction |
|---|---|---|---|
| Renderer | Pixels / views | What does the world look like? | Video and interactive visual generation |
| Simulator | 3D state / physics | How does the world behave? | Geometry, materials, physical consequences |
| Planner | Action | What should the agent do next? | Robotics, VLA models, model-based RL |
Renderers are judged on visual fidelity. Simulators produce structure: geometry, materials, physics, and consequences. Planners decide action.
The planner layer is the least solved because it requires the model not only to represent the world, but to choose useful interventions inside it.
What capabilities world models need
The valuable world models share four capabilities: predictive simulation, action-conditioning, spatial and physical intelligence, and persistent memory.
Predictive simulation means the model can roll the world forward. Action-conditioning means the world changes based on what the agent does. Spatial and physical intelligence means the model understands objects, space, motion, gravity, materials, and causality. Persistent memory means the world does not fall apart as soon as the camera turns away.
This is still hard. Interactive worlds degrade because small errors accumulate over time. A model may look convincing for a short session but lose consistency over longer horizons.
Part 2: How to Build One — Step by Step
The canonical architecture: Ha & Schmidhuber 2018
The foundational architecture is the 2018 World Models paper by David Ha and Jürgen Schmidhuber. It split an agent into three modules: Vision, Memory, and Controller.
| Component | Technical version | Job |
|---|---|---|
| Vision | VAE | Compresses raw images into a compact latent representation |
| Memory | MDN-RNN | Predicts the next latent state based on current state, action, and history |
| Controller | Linear policy | Chooses the action from the compressed state |
The Vision module compresses raw frames into a smaller latent vector. The Memory module predicts what the next latent state may look like, conditioned on the current latent state, action, and hidden history. The Controller maps the latent state into an action.
The training procedure is: collect rollouts, train the vision model, train the memory model, define the controller, then optimise the controller inside the learned environment.
The famous result was that the agent could train inside its own imagined version of the environment and transfer the learned policy back to the real environment.
The key insight is still the core of the field:
real-world interaction is expensive, but imagination is cheaper.
The modern lineage: how each generation improved
The Technology Lineage
Each generation did not fully replace the one before it. It patched the weakest joint: error drift, then real-time speed, then pixel fidelity, then geometry, then grounding in action.
2018 baseline
Fixes drift
Live and scalable
Sharper frames
Editable 3D geometry
Predicts latent representations
Robot action bridge
2018 baseline
Fixes drift
Live and scalable
Predicts latent representations
Editable 3D geometry
Sharper frames
Robot action bridge
Before going into each branch, this is the easiest way to see the evolution.
This lineage matters because world models did not evolve in one straight line. Each technical generation solved a different weakness.
The original VAE + RNN setup proved the concept: compress the world, predict the next state, and train a controller inside the learned environment. RSSM improved the memory problem by reducing drift and handling uncertainty better. Transformers made longer, more scalable sequence modelling possible. Diffusion improved visual fidelity. Gaussian splats made generated worlds more editable and spatially useful. JEPA shifted the focus from predicting pixels to predicting meaningful latent representations. VLA models then connected world understanding to robot action.
That is why the category now spans video, 3D, robotics, simulation, and planning.
Dreamer and RSSM
The Dreamer series improved the memory architecture through Recurrent State-Space Models. These split the latent state into deterministic memory and stochastic uncertainty.
Dreamer agents learn behaviours by imagining trajectories inside the model, reducing the need for real-world interactions. This matters most in robotics and autonomous vehicles, where real data collection is slow, expensive, and sometimes unsafe.
Genie and autoregressive transformers
Google DeepMind’s Genie line treats world generation more like language generation. It uses video tokenisation, latent actions, and autoregressive prediction to create interactive environments.
Genie 3 is important because it points toward real-time navigable worlds, though consistency still remains limited.
Oasis and real-time generative worlds
Decart and Etched’s Oasis is one of the clearest public examples of a real-time AI-generated game-like world. It responds to keyboard input and generates the next frames based on user action.
The point is not only that it looks like a game. The important point is that the world changes in response to user actions.
Marble and Gaussian splats
World Labs’ Marble outputs persistent, editable 3D worlds using Gaussian splats. Instead of only generating video, it creates 3D scene representations that can be exported into tools such as Unreal, Unity, Blender, and Houdini.
This makes Marble relevant for 3D design, spatial computing, games, VFX, and VR.
JEPA and V-JEPA
Meta’s V-JEPA follows the understanding-first philosophy. Instead of reconstructing pixels, it predicts abstract future representations.
This matters because physical AI needs useful representations of depth, motion, objects, and consequences, not just beautiful frames.
VLA models
VLA means Vision-Language-Action. These models connect what a robot sees, what it is told, and what it should do.

They are the practical bridge from today’s vision-language models to robot foundation models. If world models give AI a sense of consequence, VLA models help turn that understanding into action.
Infrastructure and compute
World models are expensive in a different way from language models. LLM inference is largely about moving huge weights efficiently. World-model inference has to maintain spatial and temporal consistency across frames, often in real time.
This is why NVIDIA is strategically important. The category needs GPUs, simulation frameworks, tokenizers, data pipelines, guardrails, physics engines, and deployment infrastructure. Platforms like Cosmos, Isaac Sim, Isaac Lab, and Omniverse make NVIDIA more than a hardware supplier; they make it part of the world-model development stack.
The data problem
World models need video, spatial data, interaction data, robot trajectories, and vehicle trajectories.
This is the binding constraint, especially in robotics. Real-world robot data is slow to collect, expensive, and sometimes unsafe. A robot cannot make millions of mistakes in a real warehouse as easily as a language model can process text.
The data strategy usually has three parts: collect real-world data, simulate additional scenarios, and use synthetic data to cover edge cases.
The best world-model companies are not only model companies. They are also data companies.
Part 3: How to Use and Apply Them
Getting started today
Most people will not train a world model from scratch. The practical entry point is to use platforms and products that expose world-model capabilities through APIs, tools, or interfaces.
| Tool / platform | Best for | Why it matters |
|---|---|---|
| NVIDIA Cosmos | Robotics and AV teams | Open world foundation model platform and data pipeline |
| Isaac Sim / Isaac Lab | Robot simulation and policy validation | Lets teams test robots before real deployment |
| Omniverse | Industrial digital twins | Simulates factories, warehouses, and physical systems |
| World Labs Marble | 3D design and spatial worlds | Generates persistent editable 3D scenes |
| Decart Oasis / Lucy | Interactive worlds and live video transformation | Shows real-time action-conditioned generation |
| Runway GWM | Creative worlds, avatars, and video | Extends video generation toward world models |
| MuJoCo | Robotics research | Open physics simulation for RL and embodied AI |
NVIDIA Cosmos here (Open-source)
Isaac Sim here (Open-source)
Omniverse here (Open-source)
World Lab Marbles here.
Decart Lucy 2.0 here.
Runway GWM 1.0 here.
Mujoco here (Open-source)
For creators, world models may first feel like better 3D or video tools. For robotics teams, they are training and validation infrastructure. For autonomous-driving teams, they are a way to generate rare scenarios.
Practical evaluation questions
The most important practical question is not “is this a world model?” but what role does it play?
| Question | Why it matters |
|---|---|
| Is it action-conditioned? | Without action, it is closer to video generation |
| Does it stay consistent over time? | Long-horizon memory is still hard |
| Does it understand 3D structure? | Physical AI needs geometry, not only pixels |
| Can it transfer to real environments? | Sim2real is the bottleneck |
| Is it usable in a workflow? | Export, API, latency, and cost matter |
A tool can be impressive and still not be useful. Workflow matters.
Concrete use patterns
The clearest use cases are synthetic training data, safe simulation, off-policy evaluation, edge-case generation, and counterfactual testing.
Synthetic training data helps robots and vehicles see more scenarios than real-world collection can provide. Safe simulation lets agents practise before deployment. Off-policy evaluation asks what would have happened if the agent had taken a different action. Edge-case generation creates rare, dangerous, or unusual cases at scale. Counterfactual testing asks how the world changes if lighting, object position, grip angle, camera angle, or vehicle behaviour changes.
This is where world models become valuable. They are not only content generators. They are tools for testing decisions before real-world action.
Part 4: The Landscape — Who Is Building and Applying World Models
Supply-side builders and demand-side applications across frontier labs, simulation, robotics, autonomous vehicles, gaming, video, spatial AI, and digital twins.
▣ Frontier & Foundation Labs
▣ Infrastructure & Simulation
▣ Robotics & Embodied AI
▣ Autonomous Vehicles
▣ Gaming & Interactive
▣ Creative & Video
▣ Spatial & 3D
▣ Industrial & Digital Twins
The world-model landscape has two sides: supply and demand.
The supply side includes labs, infrastructure providers, simulation companies, robotics model builders, video/world-generation startups, and autonomous-driving specialists.
The demand side includes robotics, autonomous vehicles, gaming, creative tools, 3D design, industrial automation, healthcare, science, AR/VR, and embodied agents.
Funding context
Selected disclosed rounds for world-model and physical-AI companies. Values shown in US$ billions.
The funding signal is unusually strong for such an early category. This is not just a research theme anymore; it is becoming a company-formation theme.
Capital is flowing into both sides of the category. Wayve represents autonomous-driving demand. World Labs represents spatial intelligence. AMI Labs represents the understanding-first JEPA thesis. Physical Intelligence represents robot foundation models. Decart and General Intuition represent real-time or gameplay-based world generation. Luma AI sits closer to the creative and video-native branch.
The important point is not only the headline numbers. Strategic corporates keep appearing: NVIDIA, Autodesk, Toyota, Uber, Adobe, Microsoft, and others. They are not only financial investors. They are potential customers, distribution partners, infrastructure suppliers, or ecosystem owners.
This is why the category matters. World models are not a narrow product category. They are a horizontal technology layer that can touch many physical and digital markets.
Challenges and Limitations
Temporal consistency / world degradation
Autoregressive systems generate one frame at a time and feed their output back in, so small errors can accumulate. A world may look good at first, then drift, distort, or forget what should remain stable.
The reality gap
Simulated behaviour does not automatically transfer to the real world. Real environments are messier, and closing the sim2real gap is still one of the hardest robotics problems.
Causal control vs. correlation
A model may learn that events co-occur without understanding what causes what. That is dangerous if the system is used for planning or intervention.
Compute cost
Real-time spatial consistency is expensive. World models need to handle time, space, interaction, and high-dimensional visual data, often at many frames per second.
Data provenance and licensing
Training on gameplay, video, spatial data, or internet media raises copyright and licensing questions. This is especially sensitive in gaming and creative industries.
Benchmarking and generality
There is no single agreed benchmark for how “general” a world model is. Claims about generality should be treated carefully until evaluation methods mature.
Action grounding
JEPA-style latent prediction is elegant, but converting abstract understanding into precise physical action remains hard. This is the planner bottleneck.
Conclusion: What to Watch Next
The most useful mental model for this field is the render → simulate → plan ladder.
Renderers are visible and commercial today. Simulators are becoming the strategic battleground. Planners are the unsolved prize.
Watch for four things.
First, longer stable interactive sessions. If generated worlds can remain coherent for much longer, the category becomes more useful.
Second, open models and benchmarks. Cosmos, V-JEPA, HunyuanWorld, and other open efforts matter because they let the field test and build.
Third, robotics transfer. The strongest proof will be robots learning from world models and performing new tasks in real environments.
Fourth, governance and provenance. As world simulators improve, watermarking, copyright, data rights, and misuse risks become more important.
The strategic punchline is that world models are complements to LLMs, not replacements. The likely architecture pairs an LLM for language and high-level reasoning with a world model for spatial and physical prediction, then connects both to a planner or VLA model for action.
Language models gave machines command of concepts. World models are how AI may come to grips with reality.
For now, the disciplined view is this:
renderers are real products, simulators are infrastructure, and planners are where the next decade of defensibility may be won or lost.
Glossary
| Term | Meaning |
|---|---|
| World model | An AI system that learns an internal simulation of an environment and predicts how it changes, especially in response to actions |
| Action-conditioning | Predicting the next state given an action; the defining difference between a world model and a passive video generator |
| VAE | Variational Autoencoder; compresses raw images into a compact latent vector and can reconstruct them |
| Latent space | A compressed internal representation of information |
| MDN-RNN | A recurrent memory model that predicts the next latent state as a probability distribution |
| RSSM | Recurrent State-Space Model, used in Dreamer to combine deterministic memory and stochastic uncertainty |
| JEPA | Joint Embedding Predictive Architecture; predicts abstract future representations rather than reconstructing pixels |
| VLA model | Vision-Language-Action model; maps what a robot sees and is told into motor actions |
| Gaussian splats | A 3D scene representation using many semi-transparent particles instead of traditional polygon meshes |
| Sim2real | The challenge of transferring a policy trained in simulation to the real world |
| Digital twin | A simulated version of a real physical system, such as a factory, warehouse, machine, or robot cell |
| Planner | The layer that decides what action an agent should take |

